Architecture
Libertai works on top of the aleph.im network. It uses its on-demand virtual machines (serverless). When you do a call to the API, it's going to one of the load balancers of the network that distributes your request to one of the available CRN (computing resource nodes, you can also call the API directly on one). This CRN then looks at the path (or domain) and redirects it to a specific virtual machine.
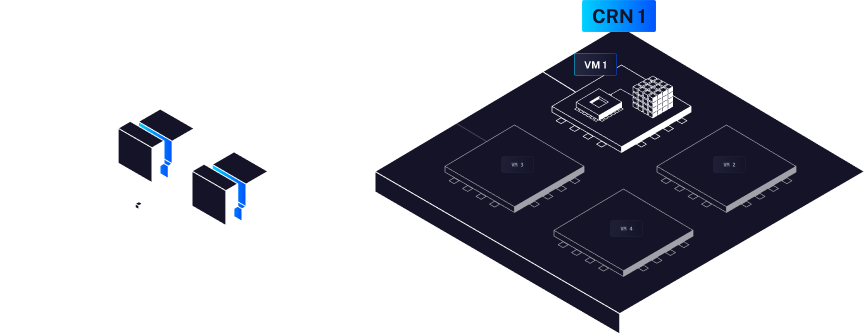
Depending on the inference stack and type of API (text generation, image generation, TTS, STT...) the inference stack will be different. On-demand, the virtual machine is started, with the inference app already on the main volume, and the model is loaded as a volume (from IPFS).
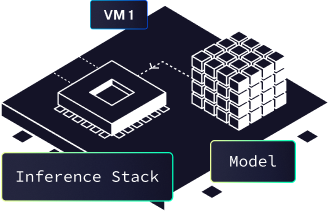
The request is passed to the inference stack, that will process the context, do the generation and get you the result back. For better performance, a cookie is set by the load balancer that acts as a sticky session, so you always end up on the same VM for faster inference on linked contexts (it's useful for text generation on chat use-cases).